谷歌AI提出新方法:在有限标记样本和训练时间内实现稳健的VRDs信息提取
在处理视觉丰富文档(VRDs)时,高效的信息提取(IE)变得越来越重要。VRDs,例如发票、账单和保险报价,在日常业务中频繁出现,且常以多样的布局和格式展示信息。自动化地从这些文档中提取数据能大幅减少人工解析的工作量。然而,从VRDs中实现IE的通用方案面临巨大挑战,因它需要同时理解文档的文本和视觉元素,这些元素难以从其他来源获取。
谷歌AI提出新方法:在有限标记样本和训练时间内实现稳健的VRDs信息提取
为了从VRDs中提取信息,已有多种方法被提出,从简单的分割算法到深度学习架构,后者能编码视觉和文本上下文。但这些方法多依赖于监督学习,需要大量的手工标注样本进行训练。
由于高度准确地标注VRDs既耗时又昂贵,这在企业环境中成为一个瓶颈,因为需要为成千上万种文档类型训练定制的信息提取器。为了应对这一挑战,研究人员开始采用预训练策略,即利用无监督多模态目标在未标注的实例上训练提取器模型,然后仅在少量手工标注的样本上进行微调。
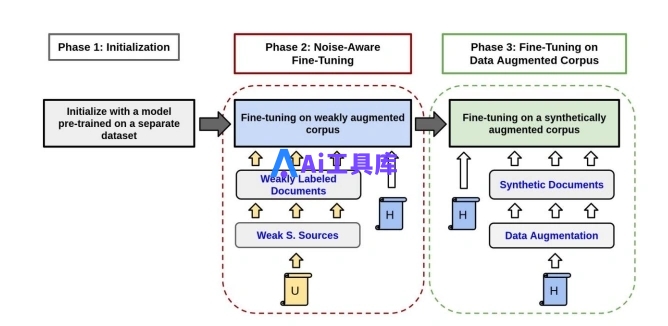
尽管预训练策略具有潜力,但它们通常需要大量的时间和计算资源,使得在有限的训练时间内变得不切实际。为了解决这个问题,谷歌AI的研究团队提出了一种半监督的持续训练方法,旨在在有限的手工标注样本和训练时间内训练出稳定的提取器。他们引入了一种称为噪声感知训练方法(NAT)的新技术。该方法分为三个阶段,利用标注和未标注的数据来逐步提高提取器的性能,同时满足训练时间的限制。
该研究的核心是推动文档处理领域的发展,特别是在企业环境中,其中可扩展性和效率至关重要。挑战在于开发技术,以便在有限的标注数据和训练时间内有效地从VRDs中提取信息。所提出的方法旨在应对这一挑战,使普通用户能够访问先进的文档处理功能,同时最小化训练定制提取器所需的手工工作量和资源。
这种半监督持续训练方法不仅解决了在严格时间限制内训练强大文档提取器的挑战,而且还带来了一系列优势。通过系统地利用标注和未标注的数据,该方法有望显着提高企业环境中文档处理工作流的效率和可扩展性,从而提高生产力并降低运营成本。该研究为普通用户访问先进的文档处理功能铺平了道路,标志着该领域取得了重要进展。